



Depending upon the above parameters you can horizontally/vertically scale a deployment to accommodate to your needs. In this blog we will briefly discuss following deployments:
Standalone deployment
Distributed deployment
Clustered deployment
Before we dive into various deployments, let us go over some of the widely used components in a Splunk deployment. Splunk comes out of the box with the following components and can be tailored suit your needs. Bear in mind – these components will be used in all the deployments except “Standalone”. Will shed more light on this later.
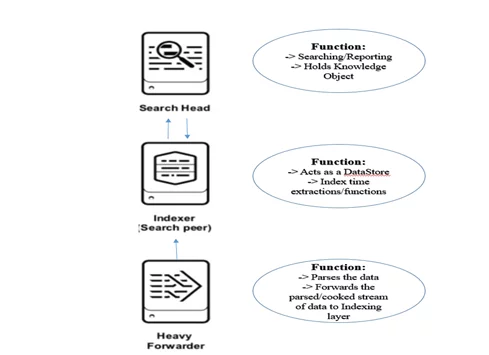
Search Head
A search head is used to – as the name suggests –search the data. Search heads get all the traffic from the end users. End users log into the UI using the search head and run their searches, reports, alerts, and dashboards and other knowledge objects.
Indexer
An indexer is used to index/parse the data. Splunk uses its proprietary algorithm to store the data in a way that it can be retrieved in a faster manner and then searched upon.
In a distributed deployment – search head (where user searches) and an indexer (where the data is stored) can be separated out. This makes sure that both of the functions i.e. searching and storing is done in a quick and efficient manner. To understand how Splunk indexes data, you can follow this link
Forwarder
A forwarder is used to – as the name suggests – forward the data to a specific target. There are two types of forwarders:
Heavy Forwarders
Lightweight Forwarders
Depending on the use case for the data and infrastructure which decide role for selecting the type of forwarder. To learn more about the difference refer this link.
Components above are represented diagrammatically as follows:
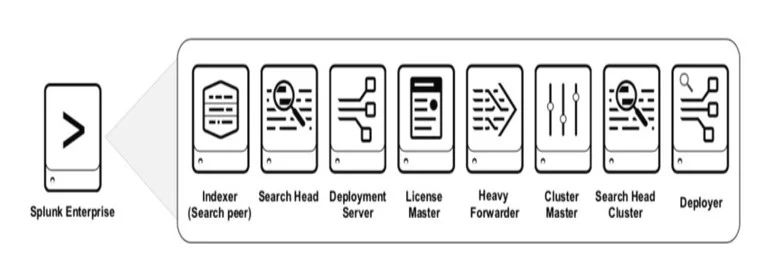
Now that we have covered understanding of basic components, let’s go over the different deployments of Splunk.
Standalone Deployment
A standalone deployment in Splunk means that all the functions that Splunk does are managed by a single instance. Various functions that a Standalone Deployment can do are:
Searching
Indexing
Parsing
Hold Knowledge Objects (This covers Reporting/Alerting/Dashboard Creation and many more)
When is this deployment type used?
This type of deployment is typically used when there are a limited number of users and a very limited amount of data flowing into Splunk.
Pros/Cons of this Type of Deployment:
Distributed Deployment
There are a few drawbacks of a “Standalone” deployment for Splunk in terms of High Availability, Disaster Recovery and Search Concurrency. To overcome some of these, Splunk can be set up in a way to distribute the tasks to different instances within the platform.
In this deployment, the roles of the Search Head, Indexers and Forwarders are split to create a distributed deployment.
To do this we need to create a distributed search. To learn more about distributed search click on this link.
We can see that we have now split the functions of each component to create a distributed environment. Find the comparison as follows:
Clustered Deployment
We can’t achieve features like High Availability and Disaster Recovery for mission-critical production deployments. To achieve this, we need a clustered deployment which looks as follows:
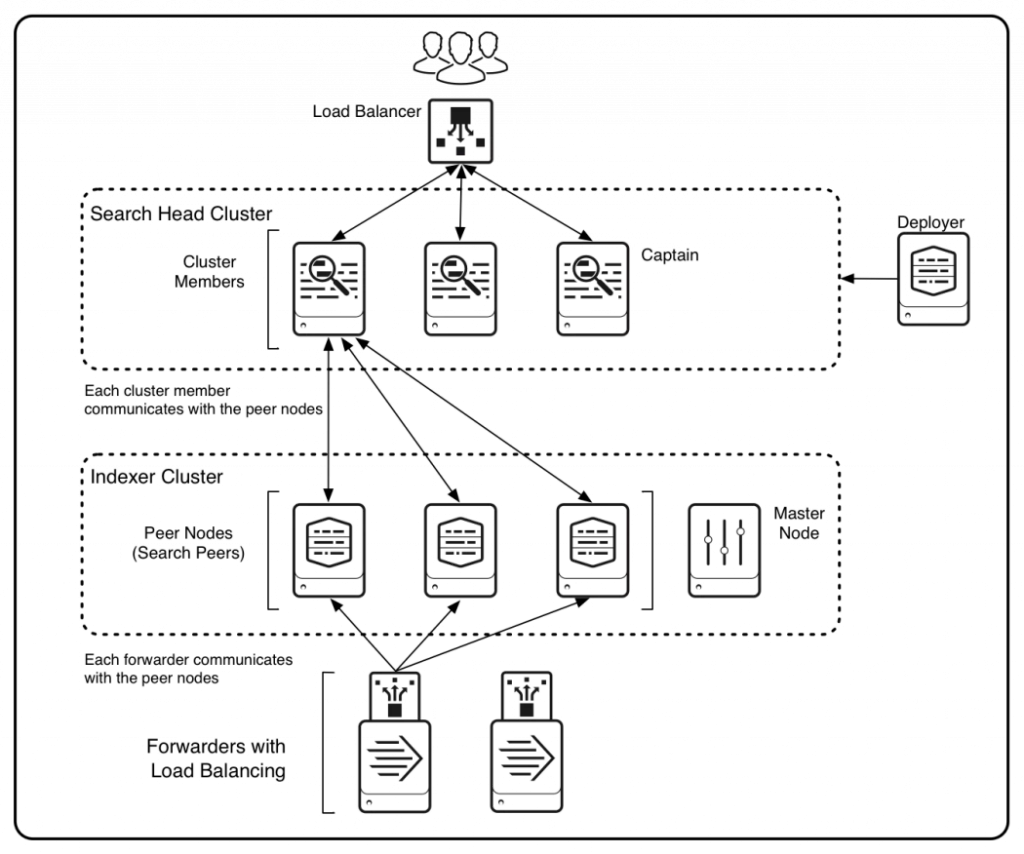
In the above deployment, the indexers are in a cluster and there is something called a “Master Node” – this Master Node or Cluster Master manages the indexers and replicates the data across multiple indexers. This creates more than one copy of data across the deployment giving the users “High Availability” of the data.
Master Node Functions:
Manages configurations/apps across all the Peer nodes/indexers
Manages incoming search requests from the search heads
Knows all the copies of the data that is indexed and replicates if any indexer goes out of service
Search Head Captain Functions:
Manages the search load coming in from users
Delegates search jobs coming in from different search head members
Replicates the knowledge bundle across the search head cluster.
We can also see the Search Heads are now in a cluster. This means that it now gives us “High Search Concurrency” which was a drawback in a previous distributed deployment.
To learn how to do indexer clustering please follow this link. To learn how to do search head clustering please follow this link.
The learn more on how to size and scale any Splunk deployments please refer this link.
This blog explains different deployments and compares them. It is suggested that once you have the basic differences between different deployments in Splunk, it is easier to architect your deployment per your needs.
Happy Splunking!
Also read: An introduction to Splunk Search Processing Language

Author
JEET THAKKAR
Jeet Thakkar is working as a Splunk Professional Services Consultant at Crest Data for 3+ years. As a senior consultant, Jeet specializes in understanding requirements and building Security and ITOps use cases for the customers. He has experience handling complex Splunk deployments with multi-terabyte Splunk licenses for Fortune 500 companies. Jeet is currently working on building DevOps solutions using technologies like Terraform, Ansible, Jenkins, and Kubernetes.




















