


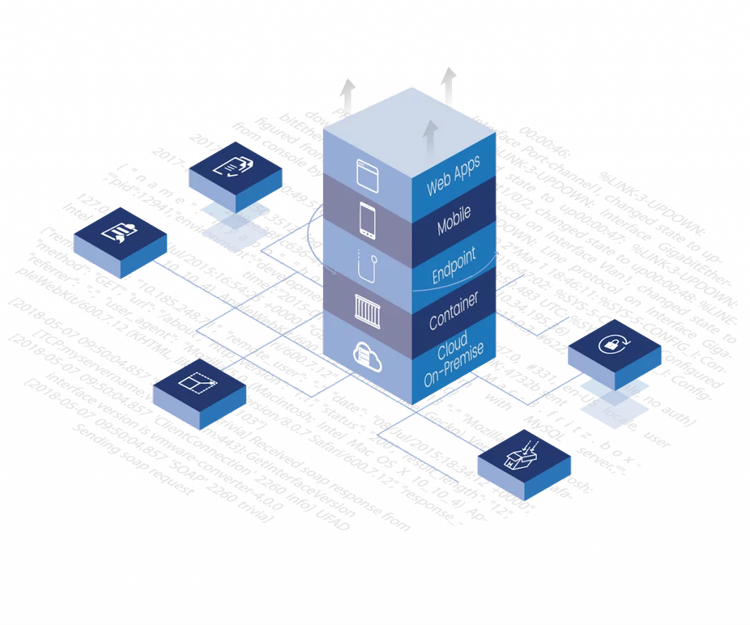


Enabling Enterprise-Scale Threat Investigations with a Browser-Based Intelligence Extension
Case Study
Enabling Enterprise-Scale Threat Investigations with a Browser-Based Intelligence Extension
Home
Executive...

Delivering High-Availability Business Applications Through a Resilient AWS Architecture
Case Study
Delivering High-Availability Business Applications Through a Resilient AWS Architecture
Home
Executive...

Scaling Enterprise Sybase Monitoring Through Datadog Integration
Case Study
Scaling Enterprise Sybase Monitoring Through Datadog Integration
Home
Executive...

Accelerating Dynatrace Migration for Better Observability and Business Outcomes
Case Study
Accelerating Dynatrace Migration for Better Observability and Business Outcomes
Home
Executive...

Accelerating Enterprise Observability with AI-Driven Migration to Dynatrace
Case Study
Accelerating Enterprise Observability with AI-Driven Migration to Dynatrace
Home
Executive...

Driving RegTech Business Growth and Operational Efficiency Through AWS Cloud Migration
Case Study
Driving RegTech Business Growth and Operational Efficiency Through AWS Cloud Migration
Home
Executive...

Modernizing Enterprise DevSecOps with an AI-Enabled, Multi-Tenant AWS Platform
Case Study
Modernizing Enterprise DevSecOps with an AI-Enabled, Multi-Tenant AWS Platform
Home
Executive...

Scaling Business Operations with a Secure AWS Cloud Platform and Advanced Identity Management
Case Study
Scaling Business Operations with a Secure AWS Cloud Platform and Advanced Identity Management
Home
Executive...

Leveraging Exposure Management Data Through Integration with Google SecOps SOAR
Case Study
Leveraging Exposure Management Data Through Integration with Google SecOps SOAR
Home
Executive...

XDR Cloud Operations Solution
Case Study
XDR Cloud Operations Solution
Home
Executive Summary
This case study details the...

















