Analyzing Open-Source Package Sustainability: Part 4 – From Clustering to Classification

Supervised learning refined our insights to build a scalable and unified model for multi-ecosystem sustainability
This is the last blog of the four blog series, if you haven't read the previous blog, we urge you to check it out here. In our previous blog, we explored unsupervised clustering methods, which provided valuable insights yet indicated the need for further refinement. Today, we're taking an exciting step forward into the realm of supervised learning.
In this blog, we'll walk you through our transition to supervised classification, share how we tackled some intriguing challenges, and reveal how we expanded our model to handle multiple ecosystems. Whether you're a data science enthusiast or a curious ML developer, there's something here for everyone!

Labeling and Model Selection: Setting the Stage
To kick off our supervised learning approach, we needed labeled data. We created a labeling system for our packages’ data with the help of composite scores we generated in a previous blog. With our data now labeled, it is time to find the optimal supervised machine learning model.
We experimented with several supervised machine learning models, but two stood out:
LGBM: Showed promising efficiency but had longer training time.
XGBoost: Offered a balance of efficiency and training time.
In the end, XGBoost emerged as the optimal model, providing the accuracy and speed we needed.
Tackling Misclassifications: Refining Our Approach
The XGBoost model’s balance accuracy was ~92%. We analysed it further with the help of the following confusion matrix:
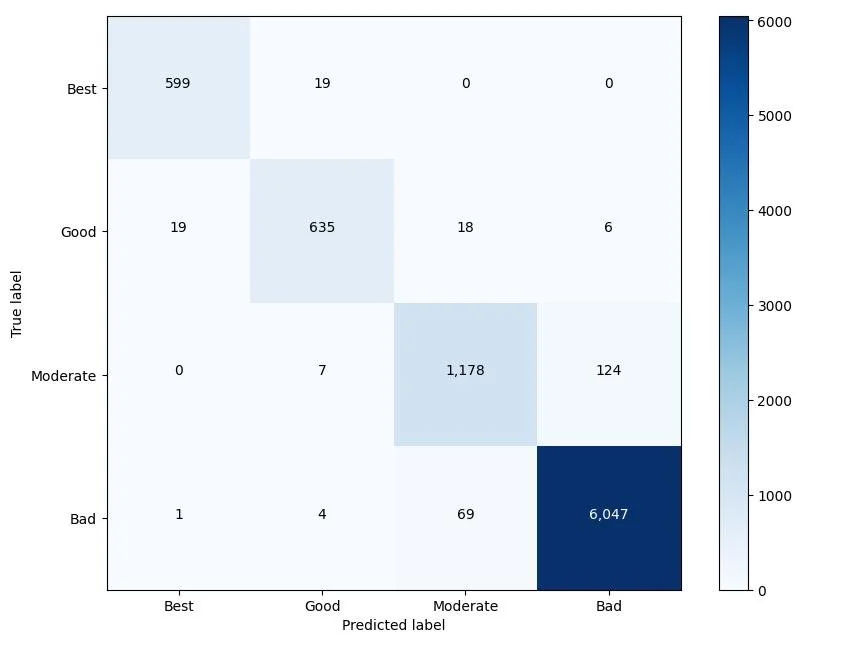
Confusion matrix of initial model on PyPI testing dataset
The model's accuracy numbers were satisfactory. However sometimes model’s accuracy can be misleading so in order to analyse results’ of model further, we also performed manual testing and encountered a couple of underlying challenges:
Bad Packages Classified as Best
We noticed a handful of packages flagged as "Bad" were being labeled as "Best." Upon investigation, we discovered these were often part of monorepos, repositories hosting multiple packages. These packages had inflated engagement metrics but lacked recent releases. To address this, we introduced a new boolean feature indicating whether a repository is a monorepo . This addition helped our model better handle these unique cases.
Confusion Between Moderate and Bad
Our model sometimes struggled to distinguish between "Moderate" and "Bad" packages. To mitigate this, we identified confusing cases and incorporated more edge examples into our training set. This helped the model learn the subtle differences more accurately.
After implementing these changes, our model showed reasonable improvements, and we were satisfied with its overall performance.
Expanding to a Combined Model for PyPI and NPM
With our model performing well on PyPI data, we set our sights on incorporating npm data. Rather than creating separate models, we opted for a unified approach, a single combined model trained on both PyPI and npm datasets.
We recognized that each ecosystem has its own unique characteristics. The distribution patterns and hidden signals in npm data differed significantly from those in PyPI. To address this, we implemented dedicated scalers during preprocessing:
A PyPI-specific scaler for PyPI data
An npm-specific scaler for npm data
This ensured that each dataset was normalized according to its ecosystem's characteristics before being merged into training data.
We then used this training data to train our XGBoost classifier. This approach not only simplified our architecture by using a single model but also made our solution scalable, opening the door to add more ecosystems in the future with minimal adjustments. Also, we tested this model on a specially curated dataset(Low confidence predictions from the last model) and our model was able to provide great results. Here is the confusion matrix for the same:
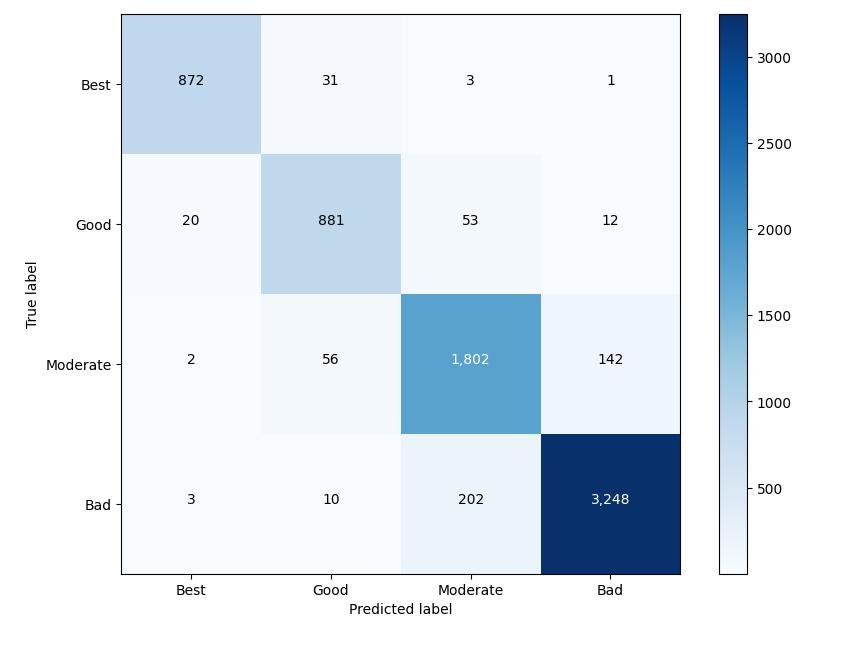
Confusion matrix of final model on curated dataset
As evidenced by the confusion matrix, our final model achieved an impressive accuracy of ~92% on a particularly challenging dataset while also providing similar results in manual testing. This demonstrates the model’s robustness and effectiveness in handling complex patterns, making it a significant achievement for us.
Next Steps: The Future of Package Sustainability Scanner (PSS)
As we look to the future, we're excited about the possibilities for PSS. Imagine integrating it directly into your CI/CD pipelines, where real-time insights about package health become part of your daily workflow.
We plan to roll out PSS as an SDK, enabling seamless integration and providing detailed vulnerability insights alongside sustainability metrics. Our goal is to broaden support to additional ecosystems, such as Go, Ruby, and more, while continually enhancing the overall user experience.
As we move forward, we're committed to refining our solution, empowering developers to make informed decisions, and ultimately ensuring that the open-source world remains secure and sustainable.
Parting Thoughts
In this final blog, we come full circle, from data gathering to finalising supervised learning model by resolving misclassifications and building a scalable, unified model for both PyPI and npm. We embarked on a journey that began with rigorous feature selection, navigated through precise data cleaning with targeted filters, explored diverse scaling strategies and ultimately led to an exceptional classification model powered by XGBoost.
As we wrap up the journey for development of PSS with the ML lifecycle, we thank you for joining us. We hope you’ve found valuable takeaways and new approaches to incorporate into machine learning endeavors. Until the next deep dive, happy modeling!