Analyzing Open-Source Package Sustainability: Part 3 – Focusing on Data Preprocessing

Effective data preprocessing is key to reducing outliers and unlocking the true potential of open-source sustainability insights
This is the third blog of the four series, if you haven't read the second blog, we urge you to check it out here. In the previous blog, we looked at efficient data fetching for analyzing open-source package sustainability. The raw data we gathered had few issues, primarily the large number of packages with zero values for critical metrics like stars, forks, issues, and PRs. These zeros distorted the overall analysis and made it difficult for an algorithm to draw meaningful insights.
In this blog we’ll walk you through cleaning and scaling the collected data in order to address issues like missing or inconsistent information, transform data into a suitable format, and create composite metrics to better assess the sustainability of open-source packages.

Sanitizing Dirty Data: Too many Zeroes
To counter the issue of high number of zeros, we decided to focus on sanitizing the dataset into a smaller but a quality subset of the data. This subset would largely depict the spectrum of usable packages across the ecosystem.
We applied carefully chosen filters to sieve out meaningful data from the fetched dataset of around 199,000 packages. Here’s the filters we used:
Open Issues and Closed Issues: One of the both values must be greater than zero.
Open PRs and Closed PRs: One of the both values must be greater than zero.
Stars and Forks: One of the both values must be greater than zero.
After applying these filters, we were left with upwards of around 80,000 packages.
Taming the Skew: Transforming the Distribution
The data quality improved after filtering out zeros but it only solved our data related issues to an extent, as shown in the figure below(grey bars). The next significant issue was to address the extreme skewness in several key metrics like stars, forks, watchers, contributors, etc. A normal min-max normalization or standard scaler won’t do justice here; hence, we explored a range of transformations, the most efficient ones can be seen in the plot below(blue bars):

Understanding the Transformations: The grey bars represent the original distribution of the 'stars' metric before applying any transformations, highlighting its extreme skewness. The blue bars show the transformed distributions using different techniques like log, square root, Box-Cox, Yeo-Johnson, and quantile transformations. The goal is to reduce skewness while preserving the underlying structure of the data. Among these, the log transformation (top middle) provides a well-balanced distribution, maintaining the natural pattern of the data while significantly reducing skewness.
Here the one that truly stood out was log transformation, Not only it smoothed the distribution, but it also maintained the natural distribution pattern, something that others struggled with.
For the time related metrics like average time to resolve issues and average time to resolve PR, we used quantile normal transformation as it had less skew and it was perfectly converted into a normal-like distribution.
Dealing with Correlation: The Composite Solution
While the skewness is now under control, we have another issue of highly correlated data to tackle before we model on the data. Supervised models can handle highly correlated data in a better way. But we weren't there yet. We were experimenting with unsupervised clustering and needed to simplify things without losing valuable information. So, our solution? Composite features.
By carefully grouping related metrics and calculating a composite score helped us condense data into meaningful composites without overwhelming the algorithms.
Activity Score: Indicates how actively a package is being maintained over time
Based on last release, commit activity, last resolved and number of releases.
Engagement Score: Reflects upon the community’s interest and interaction with the package
Based on stars, forks, contributors & watchers.
Maintenance Score: Highlights the packages’ reliability in addressing user feedback
Based on Issue closed/total ratio, PR closed/total ratio, average time to resolve issues/PRs.
The Clustering Conundrum: Lessons Learned
Armed with a dataset with clean, scaled with composite features, we tried clustering the packages into four(Best, Good, Moderate and Bad) categories using unsupervised clustering methods. The goal was to see if the natural grouping would emerge from the data without any labels.
From various clustering techniques that we tried, K-means showed the best results that are visualized in the 3D plot, with the 3 composite scores as axis as illustrated in the below figure
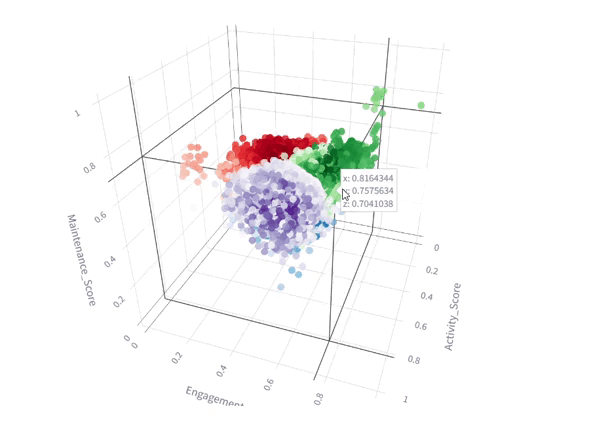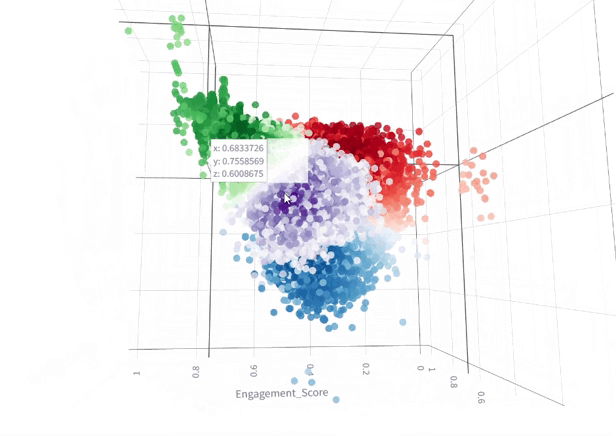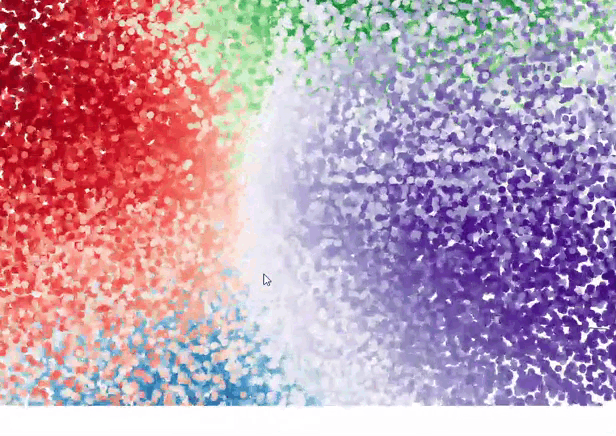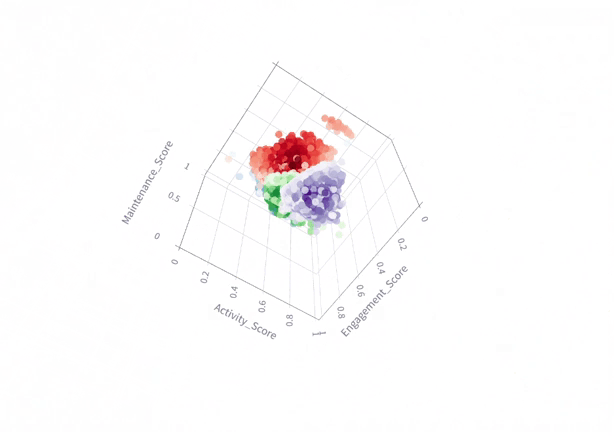
3D Plot of Clustered Data (KMeans, n=4) with Colors Indicating Classes and Shading Representing Silhouette Scores
As the visualization shows, the clusters aren’t well defined due to muffled boundaries & significant overlap among clusters. This indicates that unsupervised methods won’t be suitable for the dataset in its current form.
Next Steps?
In the next part of the series, we’ll dive into how we transitioned from unsupervised learning to supervised learning. Using labeled data, we aim to train a model that can learn patterns to classify packages into four categories effectively.
Stay tuned for the next blog where we’ll dive into how we trained models, tested and reiterated till the most effective model is formed not just in terms of raw accuracy but the usability and generalisation.